Segment's System Redesign: Solving a Scaling Crisis

Segment, the company Twilio acquired last year for $3.2 billion, was experiencing initial success in 2015 when it encountered a challenge related to expansion: its rapid growth was causing the data processing tools it had developed for its platform to exceed the capabilities of the original system architecture.
Leadership was concerned that failing to address this issue would create a significant technological limitation. While Segment, like all developing startups, desired continued growth, it also recognized the necessity of enhancing the reliability of its data platform or facing a situation where it could no longer effectively manage the volume of data flowing through its infrastructure. This presented a critical challenge for the burgeoning company.
Segment’s engineering group started a thorough evaluation of the requirements for a more dependable and scalable system. Their initial concepts underwent several refinements from late 2015 onward, and with each improvement, they achieved greater efficiency in resource management and data processing.
The resulting project was named Centrifuge, and its objective was to transmit data through Segment’s systems to customers’ desired destinations with speed, efficiency, and minimal operational expenses. The following details the development process of this system.
Growing pains
Problems within the system surfaced as is common – through customer feedback. When Tido Carriero joined Segment as chief product development officer at the close of 2015, he was tasked with identifying a resolution. The core of the problem lay in the initial system’s design, which, like many early-stage startup products, prioritized speed to market over long-term scalability, and the time to address accumulated technical debt had arrived.
“Our original integrations architecture was constructed in a manner that proved unsustainable across several areas. We were undergoing substantial growth, and our CEO [Peter Reinhardt] brought various scaling difficulties to my attention on approximately three occasions within a single month, issues that our customers or partners had raised,” Carriero explained.
The positive aspect was the platform’s ability to quickly gain customers and partners. However, this progress was at risk if the fundamental system architecture wasn’t enhanced to accommodate the significant growth. Carriero noted this created a demanding period, but his experience at Dropbox had prepared him to understand that a complete overhaul of a company’s technology platform was achievable.
“A key takeaway from my previous role [at Dropbox] is that when facing a critical business challenge, you eventually recognize that your company may be uniquely positioned to experience this issue at such a large scale,” he stated. For Dropbox, this centered on storage capacity, while for Segment, it involved the concurrent processing of extensive data volumes.
When considering whether to procure a solution or develop one internally, Carriero determined that building was the only viable path forward. No existing product could adequately address Segment’s specific scaling challenges. “This realization led us to adopt a new approach, ultimately resulting in the development of our Centrifuge V2 architecture,” he said.
Building the imperfect beast
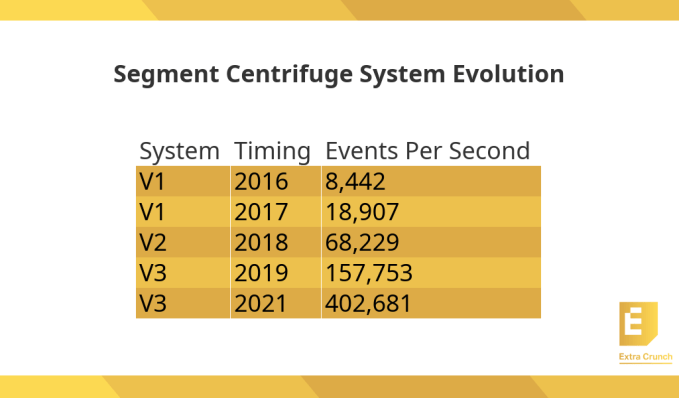
The organization initially monitored system performance while handling 8,442 events each second. By the time development commenced on V2 of its infrastructure, this figure had increased to an average of 18,907 events per second.
Although system performance difficulties began to surface in 2016, a full year of investigation and planning passed before the creation of the subsequent platform iteration. This new version would utilize a scalable architecture hosted on AWS, incorporating database clusters. The design proved effective in resolving scaling challenges, but the company quickly discovered that this solution involved significant costs.
Achille Roussel, the principal site reliability engineer and leader of the Centrifuge project, recognized a substantial issue facing the company. However, it presented the type of engineering challenge that engineers find stimulating. The initial phase involved a thorough analysis of the current system and its constraints on Segment’s continued expansion.
“After gaining a comprehensive grasp of the problem, we transitioned into the design phase and developed a solution that preserved the beneficial aspects of the existing system while rectifying its shortcomings, thereby supporting future growth,” Roussel stated.
The foundation of the updated system was containerization, leveraging Amazon ECS, AWS’s container orchestration service, and clusters of Amazon Aurora databases. “Specifically, we began with Aurora as the primary underlying technology, managing pools of MySQL databases operating on Aurora, and later on standard Amazon RDS [cloud relational databases]. This database technology formed the core of the system, with ECS serving as our preferred container scheduler. The system was fundamentally constructed upon these two components,” he explained.
Upon full deployment of V2 in early 2018, it was processing over 68,000 events per second. While the new system addressed key scaling issues encountered with the prior version, it introduced its own set of challenges, primarily the high expense associated with this cloud-based scaling approach. Furthermore, there were inherent limitations regarding the number of database clusters Segment could deploy. Lastly, its operational complexity made it difficult to onboard new team members for system maintenance.
These factors prompted the concept of developing V3, a project initiated at the start of 2019.
Achieving Optimal Performance
The engineering team was initially taken by surprise by challenges related to cost-effectiveness, which prompted them to incorporate new features designed to lower their increasing cloud expenses with Amazon. Roussel explained, “Upon launching the system, we discovered the actual costs were substantial, necessitating significant effort to manage them and ensure profitability in a production environment.”
The team also observed that the updated system presented its own set of constraints, along with a scaling issue reminiscent of the one encountered with its previous iteration.
They once again found themselves needing to identify a solution to overcome these limitations before reaching the design boundaries of V2. “Around the one-year mark, we began to recognize the limits of the design we had implemented, particularly concerning the technological decisions made regarding the auto-scaling of hundreds of MySQL databases, which had an inherent physical restriction on the number that could be initiated simultaneously.” He noted that this limitation impacted their scaling speed, making it crucial to explore potential remedies.
At this stage, they turned to Kafka, the open-source streaming events platform, which they had already been utilizing internally for certain system components. They then decided to leverage Kafka as a core element of the solution, reducing their dependence on the pools of MySQL databases hosted on AWS.
“After deciding to eliminate databases, we evaluated available options, including industry practices and our internal expertise. Kafka emerged as a highly effective component, and given our prior investment in it, with the resulting automation and cost efficiency, further investment seemed logical to capitalize on the benefits we had already realized,” he stated.
They also transitioned from ECS to EKS, Amazon’s fully managed Kubernetes service. This new system proved significantly more economical, resulting in a tenfold reduction in infrastructure costs. Crucially, the company had created a system capable of infinite scaling, preventing the scalability issues experienced with V1 and V2.
Indeed, upon deployment in September 2019, the system processed over 157,000 events per second. The latest measurement shows this number has increased to more than 400,000 events per second, demonstrating the new system’s scalability.
With the company now part of Twilio, future architectural plans will be more closely aligned with theirs, though this integration is still in its early stages. Carriero explains that, as a nimble startup, they focused on the immediate project, while a public company like Twilio plans in five-year increments.
Regardless of developments with their new parent company, Segment has developed a system that positions them for future growth with both resilience and scalability, which is a strong foundation for continued success.
Related Posts

Databricks Raises $4B at $134B Valuation - AI Business Growth

Google Launches Managed MCP Servers for AI Agents

Cashew Research: AI-Powered Market Research | Disrupting the $90B Industry

Boom Supersonic Secures $300M for Natural Gas Turbines with Crusoe Data Centers

Microsoft to Invest $17.5B in India by 2029 - AI Expansion
