Google Expands Language Support in India | Search Engine Journal

India boasts over 600 million internet users, yet only a small percentage are proficient in English. Currently, the majority of online services and a significant amount of web content are presented solely in English.
This linguistic challenge continues to exacerbate the digital gap within the world’s second-largest internet market, restricting the online experience of hundreds of millions of users to a limited selection of websites and services.
Consequently, major technology companies based in the United States, relying on growing markets like India for continued expansion, are increasingly focused on broadening access to the web and their offerings.
For example, a Google tool enabling rapid translation of web pages from English into various Indian languages has been utilized over 17 billion times by Indian users within the last twelve months.
Google, a frontrunner in this initiative, recently revealed further developments. The company – which recognizes India as its largest user base and has pledged to invest over $10 billion in the country in the years ahead – announced plans to increase investment in machine learning and artificial intelligence research within its Indian research facility, and to broaden access to its AI models throughout the technology landscape. The company also intends to collaborate with domestic startups focused on providing services in local languages, and to substantially enhance the user experience of Google products and services for those who use Indian languages.
Regarding this final point, the company today detailed a series of updates being implemented across its services to support a wider range of local languages, and introduced a novel strategy for language translation.
Product changes
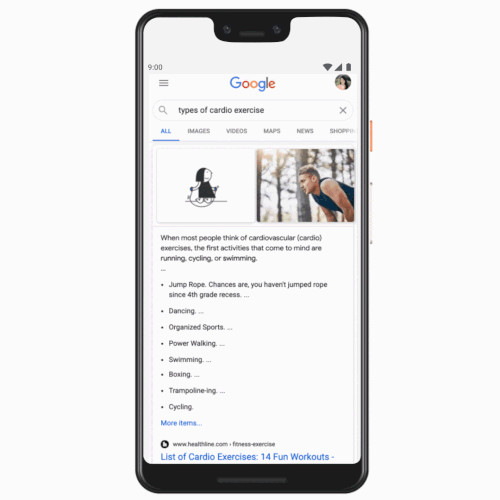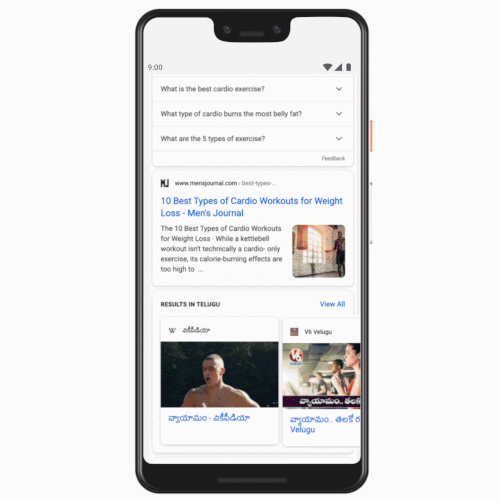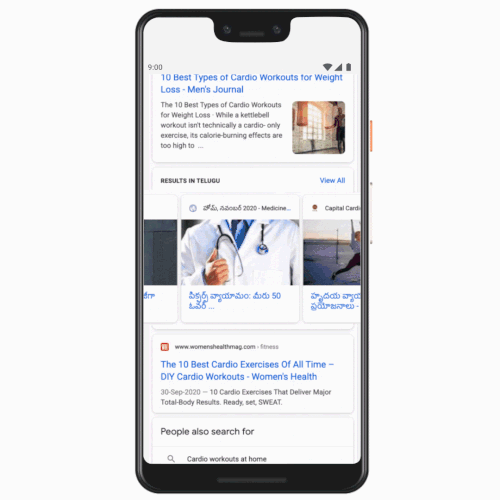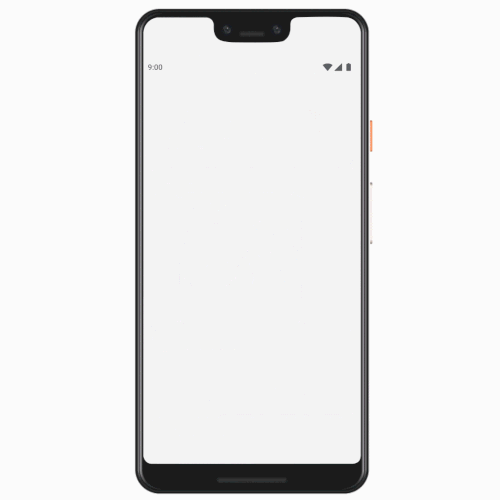
Search results are now available to users in Tamil, Telugu, Bangla, and Marathi, expanding beyond the existing support for English and Hindi. This update arrives four years after Google introduced a dedicated Hindi search tab in India. The company reported that the volume of Hindi search queries increased over tenfold following the tab’s implementation. Users who prefer Tamil, for example, can now establish a Tamil tab alongside English and easily switch between the two options.
Receiving search results in a local language is beneficial, but many individuals also wish to formulate their searches using those same languages. Google has identified that composing queries in languages other than English presents a challenge for many users. Consequently, a significant number of users conduct searches in English, even when they would prefer to view results in a local language they comprehend.
To overcome this obstacle, Search will soon begin displaying pertinent content in supported Indian languages, even when the initial query is entered in English. This functionality, planned for release over the coming month, will encompass five Indian languages: Hindi, Bangla, Marathi, Tamil, and Telugu.

Google is also streamlining the process for users to modify their preferred language for search results within an application, without needing to adjust their device’s overall language settings. This feature, currently available in Discover and Google Assistant, is now being extended to Maps, which supports nine Indian languages.
Furthermore, Google Lens’s Homework feature—which enables users to photograph a math or science problem and receive both the answer and a step-by-step solution—now includes support for the Hindi language. India represents the largest market for Google Lens, as stated by Nidhi Gupta, a senior product manager at Google India, during the announcement.
Jayanth Kolla, a chief analyst at Convergence Catalyst, suggests that the new capabilities of Google Lens could present competitive pressure to certain Indian startups, such as Doubtnut, which is backed by Sequoia Capital and operates in a similar domain.
MuRIL
Google leaders have announced a novel language AI model named Multilingual Representations for Indian Languages (MuRIL), designed to offer improved performance and precision when managing transliteration, spelling differences, and the complexities of mixed languages. According to Partha Talukdar, a research scientist with Google Research India, speaking at a virtual event on Thursday, MuRIL uniquely supports text written in Roman script for Hindi, a capability absent in earlier models.
The company developed this new model utilizing articles from Wikipedia and text sourced from the Common Crawl dataset. Training also included transliterated text, processed through Google's established neural machine translation systems, originating from sources like Wikipedia. Consequently, MuRIL demonstrates superior handling of Indian languages compared to previous, more broadly focused language models, and effectively processes letters and words that have been transliterated – meaning it utilizes the most similar characters from alternative alphabets or writing systems.
Talukdar explained that the prior model proved impractical due to the necessity of creating separate models for each language. “Developing language-specific modeling for every task is not an efficient use of resources, particularly when sufficient training data for these tasks is unavailable,” he stated. MuRIL exhibits a substantial improvement over the previous model – a 10% increase in performance on native text and a 27% increase on transliterated text. Developed by Google teams in India and utilized internally for approximately one year, MuRIL is now available as an open-source resource.
 MuRIL excels in various tasks, including accurately gauging the sentiment expressed in a sentence. Talukdar illustrated this with the example of “Achha hua account bandh nahi hua,” which was previously misconstrued as negative, but is now correctly identified as a positive statement by MuRIL. Similarly, the model can distinguish between people and places: “Shirdi ke sai baba” was formerly categorized as a place, an inaccuracy that MuRIL now rectifies by correctly identifying it as a person.
MuRIL excels in various tasks, including accurately gauging the sentiment expressed in a sentence. Talukdar illustrated this with the example of “Achha hua account bandh nahi hua,” which was previously misconstrued as negative, but is now correctly identified as a positive statement by MuRIL. Similarly, the model can distinguish between people and places: “Shirdi ke sai baba” was formerly categorized as a place, an inaccuracy that MuRIL now rectifies by correctly identifying it as a person.Related Posts

ChatGPT Launches App Store for Developers

Pickle Robot Appoints Tesla Veteran as First CFO

Peripheral Labs: Self-Driving Car Sensors Enhance Sports Fan Experience

Luma AI: Generate Videos from Start and End Frames

Alexa+ Adds AI to Ring Doorbells - Amazon's New Feature
